
Trace, TKPROF & trcsess
- Home / Tuning & Performance / Trace, TKPROF & trcsess

Neste artigo vamos falar um pouco sobre o processo de geração de “traces” dentro do Oracle, um recurso que é bastante útil quando você precisa rastrear as atividades de determinado usuário dentro da instancia de banco de dados.
Dando uma explicação bem simples e direta, o processo de gerar traces nada mais é do escrever em arquivos texto tudo o que determinado usuário fizer, para que se possa fazer uma análise posterior e para isso precisamos interagir com alguns componentes do Oracle, pois bem, vamos lá.
Imagina que você tem uma reclamação de que a aplicação está passando por problemas de lentidão em determinado ponto, aí você pergunta para o desenvolvedor quais são os comandos SQL que estão sendo executados nesta etapa (para poder começar um processo de tuning) e com a maior cara de pau ele fala: “Não sei…” (não ria, isso é mais normal do que você imagina).
Neste caso, como administrador do banco de dados, cabe a você então descobrir o que se passa e para isso, vamos usar a tal da “trace”. O primeiro passo é descobrir qual é o usuário dentro da instancia de banco de dados, em nosso caso será o usuário HR, mas na vida real você pode consultar a v$session para investigar quem é o usuário.

Repare que a coluna CLIENT_IDENTIFIER está sem valor algum, isso é porque nós não definimos esse atributo, pois ele não é carregado de maneira automática. Usamos esse tipo de identificador para marcar as sessões que queremos monitorar, para fazer isso você pode usar a procedure SET_IDENTIFIER da package DBMS_SESSION, conforme o modelo:
SQL> exec DBMS_SESSION.SET_IDENTIFIER(‘exemplo_oradata’);
Consulte a v$session novamente e verá que a agora sua sessão tem o identificador definido na execução do procedimento anterior, pois bem, ele será muito importante no processo de monitoramento da sessão.

Como você já deve ter reparado, o identificador da sessão é definido pelo próprio usuário no momento da conexão, e imaginando nosso cenário onde a aplicação já está em execução, torna-se impossível implementar este mecanismo em uma aplicação já em produção, então para conseguirmos implementar a identificação das sessões, uma trigger de banco de dados é bastante útil, veja o exemplo:
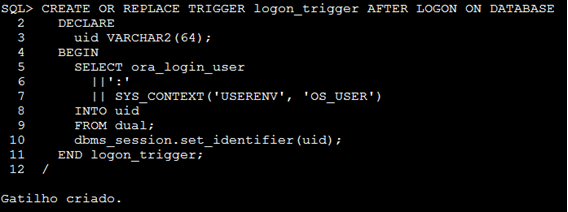
Com o uso desta trigger, toda vez que um usuário se conectar, automaticamente será atribuído a sessão dele um identificador de sessão, composto pelo usuário do banco de dados mais o usuário do sistema operacional, abra uma nova conexão com o usuário HR, e depois em uma conexão separada, como SYSDBA consulte a v$session novamente para ver o resultado.
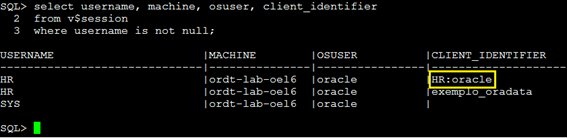
Pronto! Agora as sessões já estão sendo automaticamente identificadas, vamos então a começar a usar este identificador para coletar as estatísticas das atividades do usuário, para isso usamos a procedure CLIENT_ID_STAT_ENABLE da package DBMS_MONITOR conforme o exemplo:
SQL> exec DBMS_MONITOR.CLIENT_ID_STAT_ENABLE(‘HR:oracle’);

Uma vez que as estatísticas estão sendo coletadas, conecte com o usuário HR em uma sessão à parte, e execute alguns comandos SQL (pode ser um select em qualquer tabela do usuário) e na sequência, execute o select abaixo conectado em outra sessão como SYSDBA:
SQL> SELECT * FROM v$client_stats order by 5 desc;
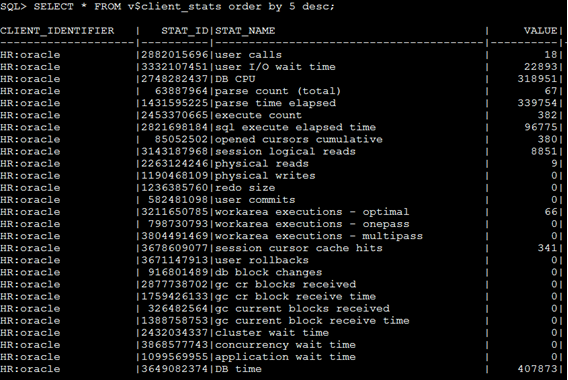
Aqui já temos uma fonte de informação muito valiosa a respeito do que está acontecendo com o banco de dados com relação as atividades do usuário em questão (o usuário HR). Com essas informações já temos base o suficiente para começar a entender o que se passa, mas essas informações, são o resultado de algumas ações do usuário, em outras palavras “quanto” está custando as ações de um usuário dentro da instancia, mas além disso, precisamos saber também “o que” o usuário está fazendo (quais comandos SQL), e para isso entra a trace, use a procedure CLIENT_ID_TRACE_ENABLE da package DBMS_MONITOR, juntamente com o identificador de sessão que criamos lá no início.
SQL> exec DBMS_MONITOR.CLIENT_ID_TRACE_ENABLE(client_id => ‘HR:oracle’, waits => TRUE, binds => FALSE);
Com a execução deste comando, você está dizendo para o banco de dados, que a partir de agora, tudo que qualquer sessão que tenha o identificador ‘HR:oracle’ fizer, uma cópia do comando executado será escrita em um arquivo de trace, juntamente com os eventos de espera da atividade (waits=>TRUE), mas não colocará no arquivo o valor das variáveis bind (binds => FALSE), o que é opcional, mas se quiser basta alterar para TRUE. Agora execute mais alguns comandos SQL para verificar que os arquivos de trace começarão a ser gerados pelo servidor.
Agora fica a pergunta. Onde serão gerados estes arquivos de trace? Para ter essa resposta, você pode consultar a view v$diag_info, nesta view há todas as informações referentes aos locais onde o Oracle gera seus arquivos de log, trace e etc. Execute o select abaixo e veja onde seus arquivos estão sendo gerados:
SQL> select value from v$diag_info where name = ‘Default Trace File’;

Fazendo uma revisão do que falamos até aqui, criamos um mecanismo que gera um identificador automático para todas as sessões do usuário a ser monitorado (em nosso caso o HR), a partir deste mecanismo, habilitamos a coleta de estatísticas das atividades deste usuário dentro do banco de dados com a procedure CLIENT_ID_STAT_ENABLE da package DBMS_MONITOR, estas estatísticas podemos encontrar na view v$client_stats. Além da coleta das estatísticas, também habilitamos o processo de geração dos arquivos de trace, através da procedure CLIENT_ID_TRACE_ENABLE da package DBMS_MONITOR, vimos também que podemos encontrar a localização dos arquivos de trace através de um select na view v$diag_info.
Agora que já conhecemos o local onde os arquivos são gerados, vamos até este diretório para ver o que encontramos por lá.
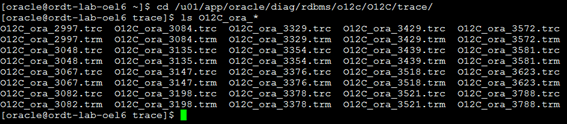
Repare que dentro do diretório, há diversos arquivos de trace (é normal) e alguns farão parte do seu processo de trace, outros não, pois esses outros, são arquivos de trace que são gerados por outros processos de trace do banco de dados. Então precisamos identificar quais são os arquivos de trace de nosso processo, mas calma! Não precisa abrir arquivo por arquivo para isso. Neste caso temos um programa chamado “trcsess” que é o responsável para fazer a unificação de todos os nossos arquivos. Para usar o “trcsess”, você só precisa informar o identificador das nossas sessões (em nosso caso ‘HR:oracle’), mais a extensão dos arquivos que vamos procurar e também um nome para o arquivo unificado que vamos gerar (em nosso caso trace_geral.trc). Veja o exemplo:
trcsess output=trace_geral.trc clientid=’HR:oracle’ *trc

Somente a título de curiosidade, você pode abrir o arquivo gerado “trace_geral.trc” com algum editor de text (vi, nano, gedit e etc). Faça isso para ver o resultado, irá aparecer alguma coisa similar a imagem abaixo:

Bom, um arquivo assim não vai agregar muito a nós pobres mortais (risos) este arquivo eu creio que só mesmo os profissionais da própria Oracle conseguem ler, mas acreditem, é neste arquivo que se encontram as informações chave para encontrarmos o que a aplicação está fazendo. Porém para isso, temos um outro programa que nos ajuda a traduzir este arquivo para uma linguagem mais legível, este programa é o “tkprof”. Usar o “tkprof” é muito simples, basta você informar o arquivo de trace original (ilegível) e também informar um nome alternativo para gerar o arquivo de tradução. Em nosso caso, vamos traduzir o arquivo “trace_geral.trc” para um arquivo chamado “trace_legivel.log”. Veja o exemplo:
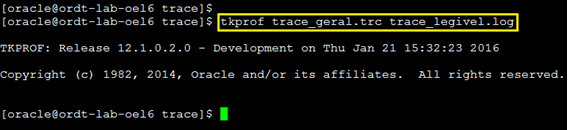
Abra o arquivo “trace_legivel.log” e veja que agora as coisas estão mais claras.
1 – Cabeçalho com uma breve tradução dos pontos mais importantes do arquivo.
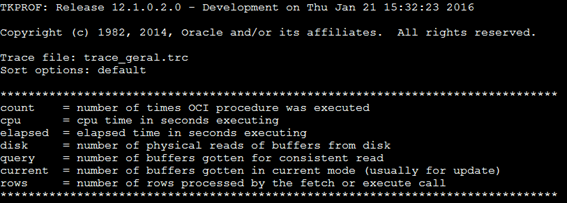
2 – Explicação das instruções SQL.
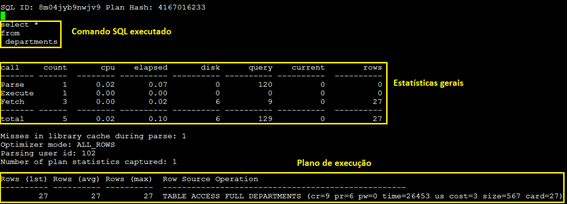
Veja que agora ficou muito mais claro, identificar cada instrução SQL que está sendo executada pelo usuário HR (em meio a várias instruções executadas por outros usuários simultaneamente), além de saber claramente também o que essas instruções estão consumindo dentro do banco de dados.
Este processo todo que falamos aqui parece ser complexo, mas não é, tente executar uma vez em algum ambiente de teste e verá que é muito simples e bastante útil, para investigar problemas de lentidão, deadlock e etc.
Dica! Use este procedimento em casos pontuais e uma vez que você conseguiu encontrar o problema, desative o processo de geração de traces, pois caso contrário, vários arquivos serão gerados no seu filesystem, o que pode deixa-lo com 100% de ocupação travando então o seu banco de dados. Para desabilitar este processo que falamos você pode usar os comandos abaixo:
Para desabilitar a coleta de estatísticas:
SQL> exec dbms_monitor.client_id_stat_disable(‘HR:oracle’);
Para desabilitar a geração dos arquivos de trace:
SQL> exec dbms_monitor.client_id_trace_disable(‘HR:oracle’);
A trigger que criamos para gerar o identificador de sessões, não há problemas em ficar ativa, de certa forma ela não vai afetar o funcionamento do seu banco de dados, mas em todo caso, você pode desabilitar a trigger ou até mesmo dar um drop dela.
É isso aí pessoal, apesar de longo e um pouco complexo, acho que esse artigo pode ajudar bastante, se você gostou deixa seu comentário, e se não gostou também!
Forte abraço e até a próxima!
Comments